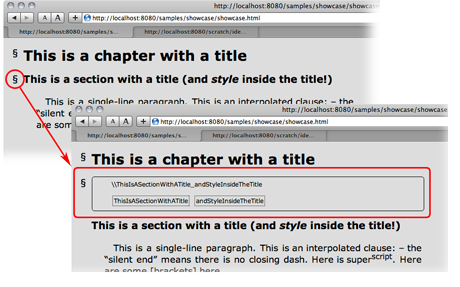
While Novelang documentation and samples are in English, Novelang already supports French characters and typography very well. I must confess there is yet no testing with other charset that ISO-8859-1 (Western European) which is (almost) perfect for both French and English.
What does happen when trying to add support for a new charset? This should be just a few additional declarations inside the grammar file. Here are Hungarian characters submitted by a reader of this blog:
ö ü ó ő ú é á ű í
Ö Ü Ó Ő Ú É Á Ű Í
First, Novelang has to read those characters as they are, provided the right charset.
According to Wikipedia, all those characters are part of ISO-8859-2 (Western Central European) charset. See: http://en.wikipedia.org/wiki/ISO_8859-2. They don’t seem to belong to Mac Roman charset. Of course, they fit perfectly into UTF-16 charset.
This is confirmed by Smultron, a text editor which cleverly refuses to save a file containing characters which don’t belong to declared charset.
Starting Novelang with -Dfile.encoding=ISO-8859-2 the two O with double agrave are rejected as unknown but other characters do pass, including the U with double agrave.
Starting Novelang with -Dfile.encoding=UTF-16 gives a lot of mess because of the two bytes instead of one.
Starting Novelang with -Dfile.encoding=UTF-16 gives a lot of mess because of the two bytes instead of one.
Starting Novelang with UTF-16 or ISO-8859-2 as default value inside novelang.parser.Encoding class, all characters do pass. This includes recompiling Novelang.
What’s the problem with -Dfile.encoding system property? I can’t tell. Anyways, this is not the right place to set the charset of source documents because this property would apply to all other files, including configuration files. So the constant inside novelang.parser.Encoding should become a configurable thing.
How configurable? I can see several useful places to set the charset.
— For the whole Novelang daemon instance (almost like -Dfile.encoding).
— For a whole Book with a source-charset command.
— For a source document read from a book using insert command.
— For currently rendered document with a source-charset query parameter (making sense only for Parts).
This would enable Books with various charsets in their Parts. Great!
Now what happens at rendering time?
PDF may render well, given the right fonts. When specifying no font directory (with --font-dirs command-line argument) there is a number sign # instead of the vowels with double grave accent. With Linux Libertine font (shipped with Novelang) those characters appear as they should.
PDF is the easy case, because it uses Unicode during all its processing, and finally embeds the fonts.
HTML is more complicated and it will never show well if user agent doesn’t provide the right font. Before that, HTML should embed the right character with the right charset.
Setting novelang.parser.Encoding to ISO-8859-2 is not enough. Characters appear correctly in HTML only with -Dfile.encoding=ISO-8859-2 set in addition. I guess this is needed for the streaming of transformation result.
Novelang passes rendered document charset as parameter to XSL stylesheets. This parameter by now reflects the constant value in novelang.parser.Encoding. Novelang’s default XSL stylesheet for HTML injects this parameter in the HTML header (meta/content/charset). What about adding a rendering-charset command for Books, and a rendering-charset query parameter? There are several things to consider.
— An XSL stylesheet defines the charset of the resulting HTML in content/charset. In the default stylesheet, this is where the value of our new rendering-charset should appear. But users may write stylesheets that don’t use this parameter.
— An XSL stylesheet may use characters outside of its own charset. This is made possible using character escape (like —), possibly through XML entity inclusion. Novelang comes with ISOlat1.pen, ISOnum.pen, ISOpub.pen standard entity sets.
— An XSL stylesheet may render characters outside of the charset of resulting document. This would be obviously the case with Books made of documents with various charsets, but this is already the case with escaped characters like OE ligatured, a character which does not appear in ISO-8859-1. Current implementation would perform unneeded escapes if rendering a document in a charset which supports OE ligatured.
From the last case, we can state this rule: “when feeding the XSL stylesheet with text, some characters which are not supported by the charset of resulting HTML must be escaped”. By now, Novelang does a bit of this inside the novelang.rendering.HtmlWriter. When feeding the stylesheet with text, the HtmlWriter calls novelang.parser.Escape#escapeHtml which avoids wrecking HTML with literal &, < and >. But escaping also occurs for OE ligatured, which plagues French users as not a part of ISO-8859-1! So we know where to plug character escaping, but this should occur depending on the charset of resulting HTML.
How could Novelang know the charset used by the output of an XSL stylesheet? The rendering-charset parameter described above offers a straightforward solution. What about some XSL metadata to express the specific charset needed by a stylesheet? Use cases are quite obscure and XSL metadata is not a simple thing. Go for the rendering-charset parameter!
In order to keep HTML source readable, character entities would be named character entities, instead of numerical ones. Sometimes – like for O with double agrave – the named entity doesn’t exist, but whenever possible, something like È is definitely more readable than È. In order to keep all definitions at the same place, named entity could appear aside of character declaration in the Novelang grammar. It just implies some extra parsing in the SupportedCharactersGenerator.
As I’m writing this post with Novelang, I realize there is no generic way to escape characters which are part of the grammar. The use case here is obvious: my source document is in ISO-8859-1 and I want those Hungarian characters to appear in the text. The novelang.parser.Escape class holds hardcoded definitions for character escapes with Unicode names (like euro-sign) and even HTML entity names as shortcuts (oelig being an alias of latin-small-ligature-oe). The novelang.parser.Escape class could feed its table from values in SupportedCharacters which is kept in sync with the grammar.
Note: the two terms charset and encoding are almost synonyms. Because W3C and ISO seem to prefer the term charset, Novelang should use the latter. This saves the more generic term encoding for other uses, which charset is clearly scoped to characters. The -Dfile.encoding system property is just badly named (and its effect is not restricted to files). See: http://en.wikipedia.org/wiki/Character_encoding.